Read Post to understand What/Why Microservices - http://arun-architect.blogspot.com/2016/11/microservices-soa.html
In the era of microservice architecture, applications are built via a collection of services. Each service in a microservice architecture solves a business problem in the application, or at least supports one and each service in the collection tends to meet the following criteria - Loosely coupled, Maintainable and testable, Can be independently deployed etc.
Microservice architectures offers different benefits.
- They are often easier to build and maintain
- Services are organized around business problems
- They increase productivity and speed
- They encourage autonomous, independent teams
- Supports different programming languages
Well despite of all such benefits, communication between microservices is the key to make it successful, else MS can wreak havoc if communication is considered ahead of time.
This post going to focus on three ways describing how services can communicate in a microservice architecture. Nothing is perfect and depends on need of the hour.
- HTTP Communication
- Message-Based Communication
- Event-driven Communication
HTTP Communication / Broker-Less Design: This is the fundamental one, where assume we have two services in our architecture. Service1 process a piece of business logic and then calls over to Service2 to run another piece of business logic.
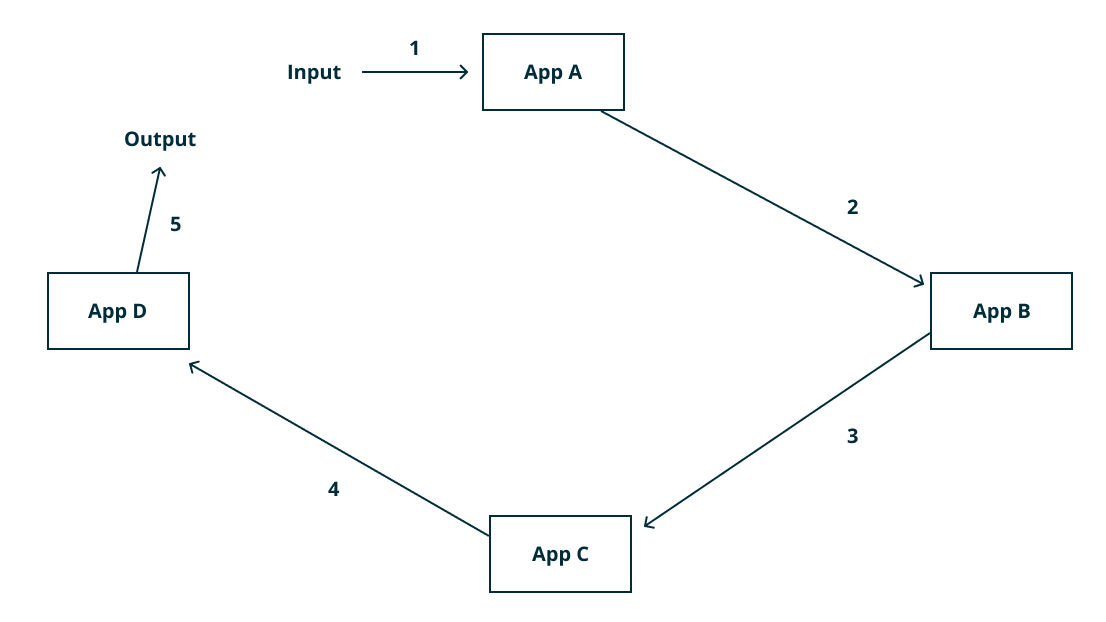
Here we make our microservices talk to each other directly. You could use HTTP for traditional request-response or use web-sockets (or HTTP2) for streaming. There is absolutely no intermediary nodes (except routers and load balancers) between two or more microservices. You can connect to any service directly, provided you know their service address and the API used by them.
HTTP calls between services is a viable option for service-to-service communication. Thus though it's basic, we could make a case that all communication channels derive from this one.
- Connection Nightmare & Resource Loss - May lead to lot of idle connections as multiple MS need to connect to each other leading lot of connections and many of those may remain fairly idle,
- Tightly Coupled: By nature, brokerless designs are tightly coupled. Imagine you have a microservice to process online payments. Now you want another microservice to give you a real-time update of number of payments happening per minute. This will require you to make modifications in multiple microservices which is undesirable.
Message Broker-Based Communication / Broker Design: Unlike HTTP communication, the services involved do not directly communicate with each other. Instead, the services push messages to a message broker that other services subscribe to. This eliminates a lot of complexity associated with HTTP communication.
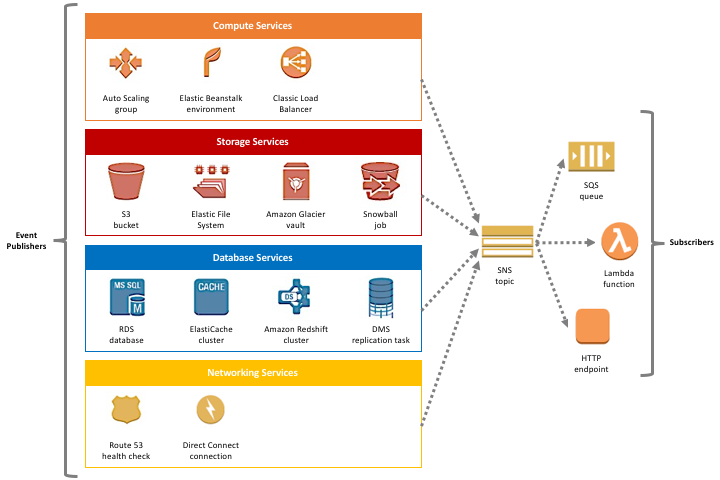
I.e. In this architecture, all communication is routed via a group of brokers. Brokers (E.g. AWS SNS, RabbitMQ, Amazon MQ, Nats, Kafka, etc.) are server programs running some advanced routing algorithms. Each microservice connects to a broker. The microservice can send and receive messages via the same connection. Here service sends messages which are then published to a particular “topic.”. This topic is read by consumers who have subscribed to it.

It doesn’t require services to know how to talk to one another; it removes the need for services to call each other directly. Instead, all services know of a message broker, and they push messages to that broker. Other services can choose to subscribe to the messages in the broker that they care about.
Amazon provides AWS SNS as message broker. Now Service1 can push messages to an SNS topic that Service2 listens on. Here is any case, calling party needs to know some identifier confirming call been placed to message broker, then broker can return the MessageId to the caller.
Sample Arch of Message Based Communication: https://aws.amazon.com/blogs/compute/building-loosely-coupled-scalable-c-applications-with-amazon-sqs-and-amazon-sns/

Event Driven Communication: This is another asynchronous approach, and it looks to completely remove the coupling between services. Unlike the messaging pattern where the services must know of a common message structure, an event-driven approach doesn’t need this.
An event-driven architecture uses events to trigger and communicate between decoupled services and is common in modern applications built with microservices.
Thus communication between services takes place via events that individual services produce. A message broker is still needed (E.g. SNS) here since individual services will write their events to it. But, unlike the message approach, the consuming services don’t need to know the details of the event; they react to the occurrence of the event, not the message the event may or may not deliver.
Every service agrees to push events to the broker (SNS here), which keeps the communication loosely coupled. Services can listen to the events that they care about, and they know what logic to run in response to them. This pattern keeps services loosely coupled as no payloads are included in the event. Each service in this approach reacts to the occurrence of an event to run its business logic. Here, we are sending events via an SNS topic. Other events could be used, such as file uploads or database row updates.
Note: An event is a change in state, or an update, like an item being placed in a shopping cart, Item placed in S3, Message pushed to SQS, Message Published to SNS etc. Events can either carry the state (the item purchased, its price, and a delivery address) or events can be identifiers (a notification that an order was shipped).
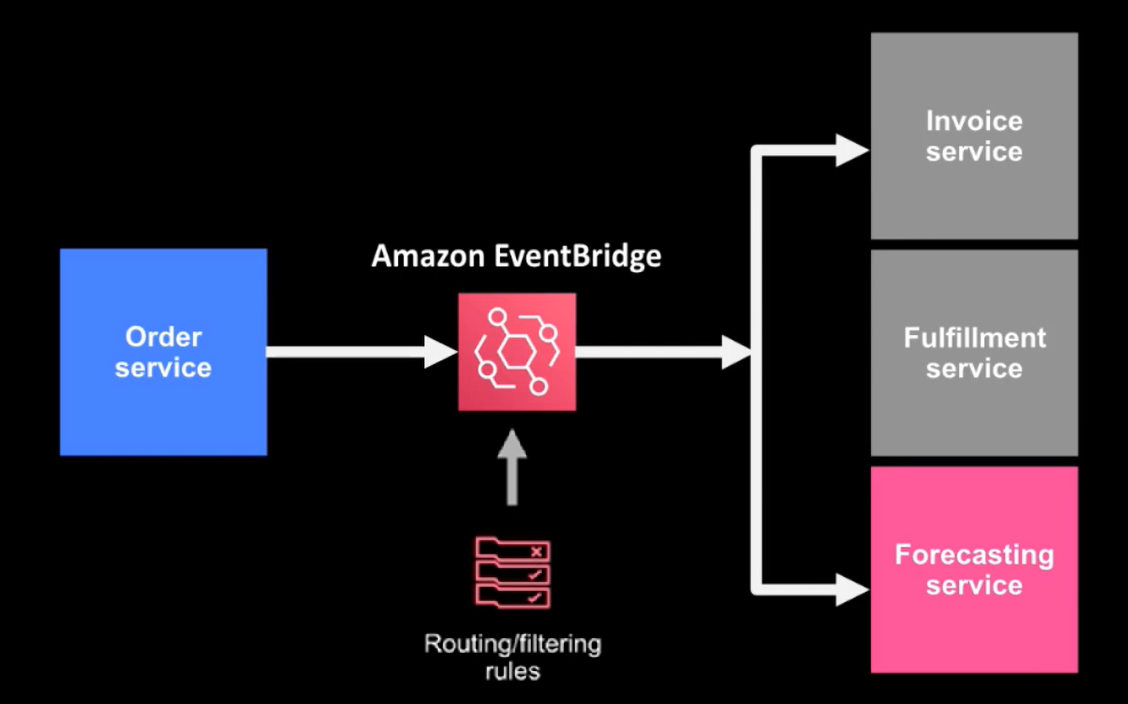
Event-driven architectures have three key components: event producers, event routers, and event consumers. A producer publishes an event to the router, which filters and pushes the events to consumers. Producer services and consumer services are decoupled, which allows them to be scaled, updated, and deployed independently.

Important Note: There are two main types of routers used in Event-driven Architectures:
- Event Topics - At AWS, AWS SNS is used to build event topics.
- Event Buses - At AWS, we offer Amazon EventBridge to build event buses
More Real Life Example of Event-Driven Communication:
Assume there is an e-commerce application having four major functions -
- Order & Inventory Mgmt - Accepts Order, Lock Inventory Item, Pass Control to Billing & Finance.
- Billing & Finance - Works on Customer Payment, Supplier Payment and Pass Control to Delivery
- Delivery - Prepares Order for Delivery
- Customer Mgmt - Manages Customer Data & Interactions.
Mapping this domain structure into Microservices, there are four microservices - Order Processing, Billing, Delivery and Customer.

With these microservices in system, assuming communication between services is thru messages, which are sent as events, below will be real Event-Driven Communication.
- Request first hits Order Processing Service.
- Once it locks the item, fires 'ORDER_PROCESSING_COMPLETED' event.
- As it's Event Driven Design, there can be multiple services listening to this event. Here Billing Service picks up the event and starts processing payment. Also Sub-Microservice 'Inventory Service' picks for updating Inventory.
- Billing Service then makes billing and fires 'PAYMENT_PROCESSING_COMPLETED' Event.
- This event is further listen by 'Delivery Service' and makes delivery and finally fires another event as 'ORDER_DISPATCHED'

Benefits of an event-driven architecture
- Scale and fail independently - By decoupling your services, they are only aware of the event router, not each other. I.e if one service has a failure, the rest will keep running.
- Develop with agility - You no longer need to write custom code to poll, filter, and route events; the event router will automatically filter and push events to consumers.
- Audit with ease - An event router acts as a centralized location to audit your application and define policies.
- Cut costs - Event-driven architectures are push-based, so everything happens on-demand as the event presents itself in the router. This way, you’re not paying for continuous polling to check for an event.
Hope this helps!!
Arun Manglick


